Scalable WebSockets
Spec Version: v2025-10-01-draft
Ecosystem Compatibility: v0 (Current) / v1 (Preview)
- v0 (Current): Celerity::1 development environment for running WebSocket API applications. Usually, the development environment will only run a single node for a WebSocket API application; however, the behaviour defined in this document will be baked into the runtime in preparation for v1.
- v1 (Preview): Multi-cloud deployments of WebSocket APIs as containerised applications using the Celerity runtime.
Read more about Celerity versions here.
Overview
The Celerity runtime supports deployment as a horizontally scalable cluster of WebSocket servers. The approach is to allow for multiple WebSocket servers to be deployed in a way in which it does not matter which server a client connects to. This is made possible by using a shared message broker that is used to publish messages to other nodes in the cluster. Each node will then filter messages received from other nodes based on the target connection ID for the message and the clients that are connected to the node.
The Celerity runtime uses Redis OSS1 pub/sub as the message broker for publishing messages to nodes in the cluster. This allows for a scalable and efficient way to handle WebSocket connections and messages. For improvements in reliability, this may be extended in the future to support message brokers with more robust delivery guarantees.
The runtime also uses Redis OSS1 to store mappings of connection IDs to node groups, allowing for the runtime to select the channel to publish messages to in an efficient manner.
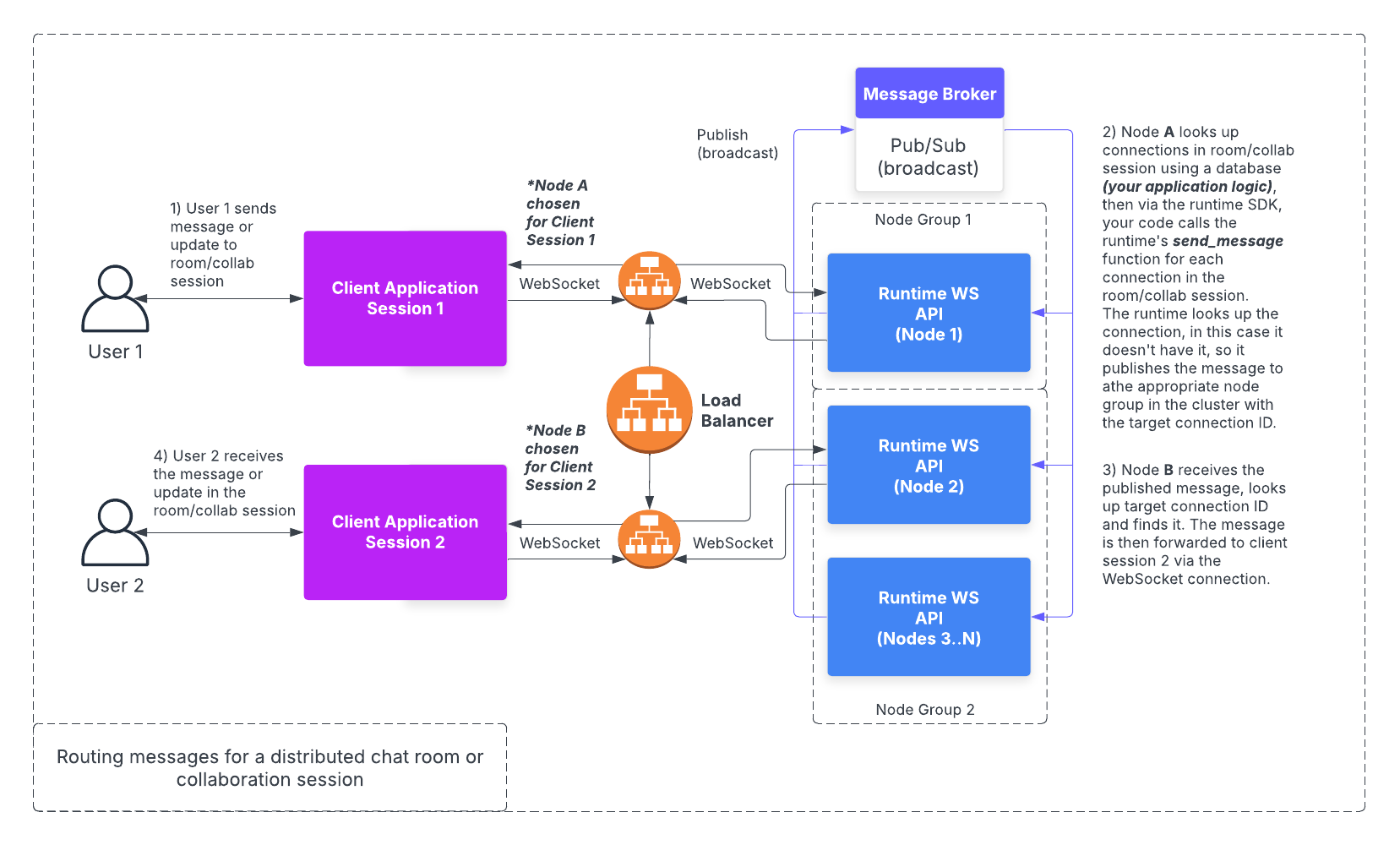
This diagram is a high-level overview of the flow for a WebSocket API cluster that doesn't include details about acknowledgements and message deduplication.
Startup Process
When a node starts up, it will connect to the message broker and will join any node group with capacity or start a new node group. To select the node group to join, it will first list the channels that match the node group pattern and then check the number of subscribers to each channel. The node will then join the node group with the lowest number of subscribers that has capacity, if no node group has capacity, the node will start a new node group. The ID created for a new node group should be a random, unique and compact ID such as a NanoID. This will have a final form of celerity:node-group:${id}.
The node group pattern is celerity:node-group:* and the node group ack pattern is celerity:node-group-ack:*.
Only the node group channel should be used to determine the node group to join, the node group ack channel will then be a mirror of the node group channel that is only used for acknowledgements.
The same configurable capacity for node groups needs to be shared across all nodes in the cluster, this defaults to 5 nodes.
The process of joining a node group is done by subscribing to the node group and node group ack channels and keeping the node group ID in memory to be used in connection management and message handling.
Connection Management
When a client connects to a node, the node must add the connection ID to the node group that the node is a member of. This is done by writing the connection ID to group mapping to the shared store. The key should be in the form of celerity:conn:${connectionId} with the value being the node group ID.
When a client disconnects from a node, the node must remove the connection ID from the node group that the node is a member of. This is done by removing the connection ID to group mapping from the shared store.
Publishing Messages
When a node receives a message from a WebSocket client, it will first check if the connection ID is for a connection that is connected to the node. If it is, the message will be processed by the node. If it is not, the message will be published via the message broker to a subset of nodes that are more likely to be connected to the target client.
To determine the channel to send the message to, the node will look up the node group by the connection ID. Node groups are used to prevent the need to broadcast every message to every node in the cluster. Groups are used to reduce the amount of channels that need to be managed by the message broker while still providing the benefits of reducing the number of messages that need to be processed by each node.
The node will then publish the message to the channel for the node group and listen for an acknowledgement for the message, see the next section for more details on acknowledgements.
Acknowledgements
Every time a message is sent to a node group in the cluster, the unique identifier of the source node will need to be included to allow for listening to acknowledgements that will be published by the upstream node that is connected to the target connection ID for the message.
The sender node will be listening for acknowledgements on the ack channel for its node group. It will then filter the acknowledgements based on the source node ID of the message and update the status of the message for the provided message ID. If an acknowledgement is not received by a configurable timeout, the sender node will publish the message again to the node group. This will continue until the acknowledgement is received or a maximum number of retries is reached. If the maximum number of retries is reached, the sender node will mark the message as lost and ensure that clients that should be notified of the lost message are informed.
See the Lost Messages section for more details on how lost messages are handled.
Handling Duplicates
Each node will keep track of messages that it has received and has been able to successfully forward to the client. This is done by storing the message ID in the shared store. The key should be in the form of celerity:msg:${messageId} with the value being 1. These entries must expire after a configurable timeout (defaulting to 5 minutes) to prevent the shared store from growing indefinitely.
Writing message IDs to the shared store is done in batches to reduce the number of writes to the shared store when there is a high volume of messages. The batch size defaults to 100 messages but is configurable, the window for flushing the batch even if the batch size is not reached defaults to 50 milliseconds and should be kept small to prevent duplicates from being missed.
Reads to check if a message ID has been processed are immediate, batching only applies to writes.
The timeout should be chosen carefully based on the acknowledgement timeout and the maximum number of retries, the message processed entry TTL should be set for a value that is greater than the acknowledgement timeout multiplied by the maximum number of retries.
Using a shared store allows for other nodes to be able to detect duplicates for messages that are being resent due to an acknowledgement timeout. This will not protect against the same message being sent multiple times with a different message ID, it is the responsibility of the application layer to handle content-based deduplication.
If a a batch request to write message IDs to the shared store fails, the node will not be able to detect duplicates for messages that are being resent due to an acknowledgement timeout. This will result in the message being resent multiple times to the client.
If a read request to check if a message ID has been processed fails, the message will be processed, where message delivery is prioritised over deduplication.